
A test passes. Then fails. Then passes again. Nothing changed.
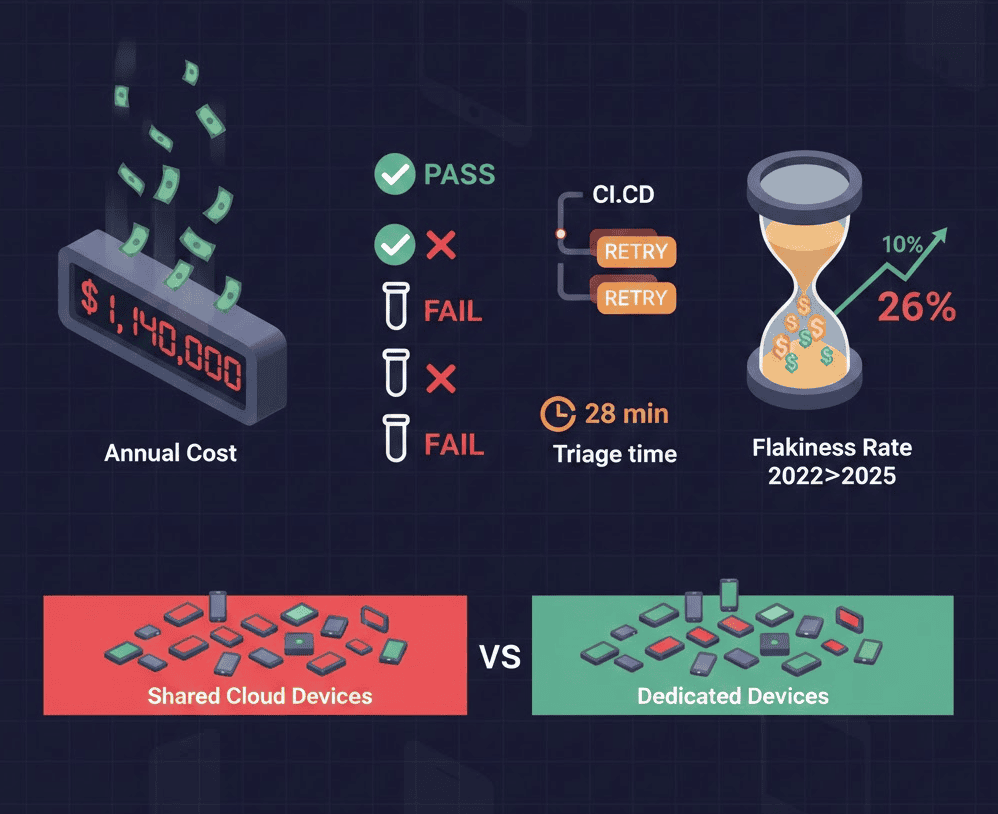
Every mobile engineer knows this pattern. What most don’t know: Microsoft calculated flaky tests cost them $1.14 million per year in developer time alone.
That’s not a typo. That’s the quantified cost of tests that can’t be trusted.
The Numbers Nobody Wants to See
Google’s engineering productivity team tracked flaky tests across their massive codebase. The findings:
- Flaky tests account for 16% of all test failures
- Flaky tests take 1.5x longer to fix than deterministic failures
- Engineers lose approximately 20 minutes per duplicate bug just determining if a failure is flaky or real
- Overall, flaky tests consume over 2% of coding time
For a 50-developer team at $120,000 average salary, that 2% translates to losing one full-time engineer annually. But salary is just the beginning. The real cost compounds through delayed releases, missed bugs, and eroded trust in the entire testing process.
Mobile Flakiness Is Getting Worse
The Bitrise Mobile Insights report tracked mobile-specific test reliability from 2022 to 2025. The trend is alarming:
Flaky test likelihood: 10% (2022) → 26% (2025)
More than one in four mobile test runs now produces unreliable results. This isn’t a minor annoyance—it’s a fundamental breakdown in the feedback loop that CI/CD depends on.
Why the acceleration? AI-generated code is flooding pipelines with more tests than ever. Each new test is another opportunity for flakiness. Without corresponding investment in test infrastructure, the noise overwhelms the signal.
What Slack Learned the Hard Way
Slack’s mobile team publishes transparent engineering metrics. Before implementing automated flaky test handling, their numbers were brutal:
- Main branch stability: 20% pass rate
- 57% of build failures came from flaky or failing automated tests
- 28 minutes per PR spent on manual flaky test triage
They built an automated detection and suppression system. The results:
- Test job failures dropped from 57% to under 5%
- 553 hours of triage time saved (28 min × 1,185 PRs)
- Developer sentiment shifted from frustration to confidence
The investment paid for itself within months. But most teams don’t have Slack’s engineering resources to build custom infrastructure.
The Trust Erosion Problem
The most expensive consequence of flaky tests isn’t measurable in hours or dollars. It’s the gradual erosion of trust.
When tests fail randomly:
- Engineers start ignoring failures (“It’s probably just flaky”)
- Real bugs hide under the noise
- The test suite becomes a checkbox rather than a safety net
- Quality gates become theater
Google’s testing blog describes the psychology: “Engineers tend to trust passing test results, but they often retry failing tests a number of times on the same version of code and consider failures followed by passing results as flaky.”
This asymmetry is dangerous. A passing test means something. A failing test might mean nothing. Once that doubt enters the system, the entire value proposition of automated testing collapses.
Why Mobile Tests Are Especially Flaky
Mobile testing introduces unique flakiness vectors that web testing doesn’t face:
Device state variability: Battery level, available memory, background processes, network conditions—all change between test runs. A device that passed 100 tests yesterday might fail today because a system update changed timing characteristics.
Framework abstraction layers: Appium, the most popular cross-platform framework, runs on top of native frameworks (XCUITest for iOS, Espresso for Android). Each layer adds latency and synchronization opportunities for failure.
BrowserStack’s documentation acknowledges this directly: “Appium (higher flakiness) vs XCUITest (more reliable).” Kobiton’s framework comparison notes that “Appium scripting bears the issues of brittle and flaky tests.”
Shared device infrastructure: Cloud testing platforms optimize for utilization, not isolation. Your test runs on a device that just finished someone else’s test. Residual state bleeds through.
Network-dependent operations: Every command travels from your CI server to the cloud platform to the device and back. Latency spikes cause timeouts. Connection drops cause mysterious failures. This is a major reason Appium tests fail in CI but pass locally.
The Framework Flakiness Hierarchy
Not all test frameworks create equal flakiness risk. Based on documentation from BrowserStack, Kobiton, Sauce Labs, and SmartBear:
Lowest flakiness: Native frameworks (Espresso, XCUITest)
- Direct UI thread synchronization
- No network round-trips during execution
- Automatic wait handling built into the framework
Medium flakiness: Purpose-built tools (Maestro, Detox)
- Designed specifically for mobile with flakiness mitigation
- Built-in retry mechanisms
- Simpler architecture than Appium
Highest flakiness: Cross-platform abstraction (Appium)
- Additional communication layer over native frameworks
- Network latency on every command
- Timing synchronization across multiple systems
Espresso’s documentation highlights its approach: “UI thread synchronization and idling resources ensure tests run only after UI operations are complete.” XCUITest offers similar guarantees for iOS. For a deeper look at Maestro’s flakiness handling, see Maestro Flakiness: A Code Deep Dive.
Appium trades stability for flexibility. The ability to write one test for both platforms comes at the cost of reliability on each platform. If you’re struggling with Appium specifically, see our complete guide to fixing flaky Appium tests.
The Hidden Multiplication Effect
Flaky tests don’t just waste time individually. They compound across your test suite.
Consider a suite of 100 tests, each with 95% reliability (only 5% flaky—better than average):
- Probability all 100 pass when they should: 0.95^100 = 0.6%
A 95% reliable test suite has less than 1% chance of a clean run. At 99% individual test reliability, you still only get a 37% chance of all tests passing.
This is why teams report “the build is always red.” It’s not that tests are failing constantly—it’s that with enough tests, something is always flaky.
The math gets worse with parallelization. Running 10 parallel streams means 10 opportunities for environmental flakiness on every test cycle.
What Microsoft Changed
Microsoft’s journey with flaky tests offers a blueprint. Their engineering research team published findings from a company-wide initiative:
Detection: They built “Deflaker” to automatically identify and quarantine flaky tests before they polluted results.
Policy: A company-wide rule required teams to fix or remove flaky tests within two weeks. No exceptions.
Metrics: They created a “flaky test score” for each project, integrated into engineering health dashboards.
Results:
- 18% reduction in overall test flakiness within six months
- 2.5% increase in developer productivity
- Millions of dollars in saved engineering time
The key insight: treating flaky tests as technical debt rather than background noise. Allocating sprint time specifically for test reliability.
The Infrastructure Variable
Much of mobile test flakiness traces back to infrastructure rather than test code:
Cloud platform contention: During peak hours, tests queue for devices. Timeouts trigger. Retries compound the queue. BrowserStack’s 15-minute queue timeout means tests can fail before they even start.
Shared device state: Cloud devices serve multiple customers. Residual apps, cached data, and modified settings carry over between sessions. A test that expects a clean device encounters contamination.
Network path complexity: Your CI server → Cloud API → Device management → Actual device → Back through all layers. Each hop introduces latency variance and failure potential.
Device health drift: Devices in large farms develop quirks. Battery degradation, storage accumulation, OS update inconsistencies. Cloud providers manage thousands of devices; some percentage are always marginal.
The common thread: infrastructure you don’t control introduces variability you can’t debug.
The Retry Tax
Most teams cope with flakiness through retries. If a test fails, run it again. Maybe twice. The logic seems sound: if it’s truly flaky, it’ll pass on retry; if it’s a real bug, it’ll fail consistently.
The cost is higher than it appears:
Direct time cost: A 3-minute test that retries twice takes 9 minutes when it flakes. Across a suite of 500 tests with 10% flakiness, that’s 150 extra minutes per run.
Queue multiplication: Cloud platforms charge by parallel execution. Retries consume the same parallelism as first attempts. Your effective parallel capacity drops proportionally to your flakiness rate.
False confidence: A test that passes on the third try might be masking a real bug that manifests under specific conditions—exactly the conditions your users will encounter.
Debugging misdirection: When a test fails, engineers investigate. If it passes on retry, that investigation time is wasted. Google estimates 20 minutes per false alarm just to determine it’s flaky.
GitLab’s survey found 36% of developers experience delayed releases due to test failures at least once a month. Most of those delays trace back to flaky tests requiring investigation and retry cycles.
What Actually Works
Teams that have tamed flakiness share common approaches:
Quarantine automatically: Don’t let flaky tests block CI. Detect them statistically (fails sometimes, passes sometimes on same code) and move them to a non-blocking suite. Slack’s system does this automatically.
Fix or delete within a time window: Microsoft’s two-week policy forces decisions. A flaky test that’s been flaky for six months isn’t providing value—it’s consuming resources.
Invest in infrastructure stability: Dedicated devices eliminate shared-state contamination. Controlled network paths eliminate latency variance. Local execution eliminates cloud queuing.
Choose frameworks intentionally: If reliability matters more than cross-platform code reuse, native frameworks (Espresso, XCUITest) outperform abstraction layers (Appium). The 1.5x debugging cost of flaky tests may exceed the 2x cost of maintaining separate test suites.
Monitor CI like production: Set reliability targets. Alert when flakiness exceeds thresholds. Review pipeline health alongside feature metrics. Bitrise’s data shows teams using observability tools see measurable reliability improvements.
The Dedicated Device Advantage
Cloud platforms optimize for one metric: device utilization. Every minute a device sits idle is lost revenue. This economic pressure directly opposes test reliability.
Dedicated devices flip the economics:
No shared state: Your tests run on your devices. Previous test contamination is your own contamination—predictable and debuggable.
No queue delays: Peak hours don’t affect your device availability. Release week doesn’t mean competing for resources.
No network variability: Tests execute locally or over controlled connections. Latency is consistent, not dependent on cloud platform load.
Predictable costs: A device costs the same whether you run 10 tests or 10,000. No retry tax on your infrastructure bill.
The tradeoff is operational responsibility. You manage the devices. But that responsibility comes with control—the control to eliminate flakiness sources that cloud platforms can’t address.
Calculating Your Flaky Test Cost
A rough formula for annual flaky test costs:
Engineers × Avg_Salary × Time_Percentage_On_Flakiness
+ (Retry_Rate × Test_Duration × Test_Runs_Per_Day × Cloud_Cost_Per_Minute)
+ (Delayed_Releases × Release_Delay_Cost)
+ (Escaped_Bugs × Bug_Fix_Cost)
For a 20-engineer team:
- 30 min/day on flakiness at $150K average = $375,000/year in direct time
- 10% retry rate on 2-hour test suite running 10x/day at $0.10/min = $43,800/year in cloud costs
- 2 delayed releases per quarter at $50K opportunity cost each = $400,000/year
Total: $818,800/year—and that’s before counting bugs that escape due to ignored failures.
Microsoft’s $1.14 million figure starts looking conservative.
See the full comparison: Mobile Device Cloud Pricing 2025
The Path Forward
Flaky tests aren’t inevitable. They’re a symptom of infrastructure and process choices that prioritize convenience over reliability.
The teams that ship confidently have made different choices:
-
Treat test infrastructure as production infrastructure. Same monitoring, same reliability targets, same incident response.
-
Invest in detection and quarantine automation. Manual triage doesn’t scale. Slack proved automated handling works.
-
Choose device infrastructure that eliminates variability. Shared cloud devices introduce flakiness you can’t fix. Dedicated devices give you control.
-
Make flakiness visible. Dashboard it. Alert on it. Include it in engineering health metrics. What gets measured gets managed.
The cost of flaky tests compounds daily. The cost of fixing the infrastructure is a one-time investment.
Microsoft saved millions. Slack saved 553 hours. Your team’s numbers are waiting to be calculated—and then reduced.
Frequently Asked Questions
How much do flaky tests cost engineering teams?
Microsoft estimated flaky tests cost them $1.14 million per year in developer time alone. Google’s engineering productivity team found flaky tests consume over 2% of coding time—equivalent to losing one full-time engineer annually for a 50-person team. The true cost includes delayed releases, escaped bugs, and eroded trust in the testing process. For a typical 20-engineer team, annual flaky test costs can exceed $800,000.
What percentage of mobile tests are flaky?
According to Bitrise Mobile Insights, mobile test flakiness rose dramatically from 10% in 2022 to 26% in 2025. This means more than one in four mobile test runs now produces unreliable results. The acceleration correlates with increased AI-generated code and expanded test suites without corresponding investment in test infrastructure reliability.
Why are Appium tests more flaky than native frameworks?
Appium adds an extra communication layer on top of native frameworks like Espresso and XCUITest. Every test command travels through network calls rather than direct UI thread integration. This additional abstraction introduces timing issues, network latency, and synchronization problems. Native frameworks handle wait conditions automatically through direct UI thread synchronization, while Appium must coordinate across multiple systems. BrowserStack and Kobiton documentation explicitly acknowledge Appium’s higher flakiness compared to native frameworks.
How can teams reduce flaky test costs?
Leading teams use several proven approaches: (1) Automated flaky test detection and quarantining—Slack reduced test job failures from 57% to under 5% using this method, (2) Time-boxed fix-or-delete policies—Microsoft requires teams to address flaky tests within two weeks, (3) Dedicated device infrastructure to eliminate shared-state contamination from cloud platforms, and (4) Treating CI reliability as a production-grade concern with monitoring, alerts, and reliability targets.
Sources: Google Testing Blog, Microsoft Research, Slack Engineering, Bitrise Mobile Insights 2025, GitLab Developer Survey
See how DeviceLab compares to the giants: vs BrowserStack | vs Sauce Labs | Read the Cost Analysis →